Нейросеть-переводчик научилась называть молекулы не хуже химиков
У химических веществ есть названия и формулы. Например, C₂H₅OH – это формула, а «этанол» или «этиловый спирт» – это названия. На заре развития науки химии веществам давали простые (их ещё называют тривиальные) названия, но по мере того, как число изученных молекул росло в геометрической прогрессии, доступные слова для молекул быстро закончились.
Как-никак, химических элементов не только больше, чем букв в любом алфавите, но и соединяться они могут в «слова» длиной в несколько сотен букв и больше, что невозможно даже в немецком языке с его Donaudampfschiffahrtsgesellschaftskapitän. Да и самим химикам хотелось навести какой-то порядок в химической терминологии. Так появилась система наименований химических соединений – номенклатура ИЮПАК, которую разрабатывает Международный союз теоретической и прикладной химии.
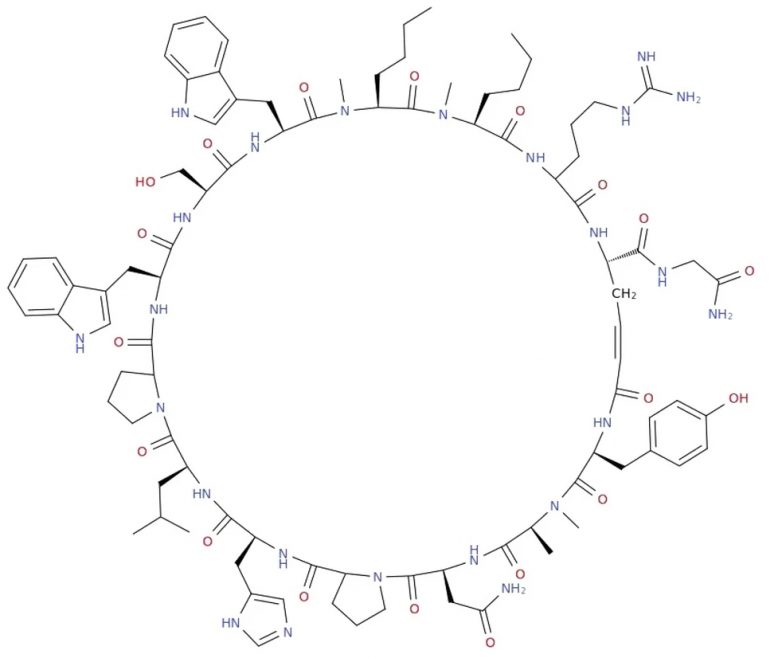
Пример молекулы циклического пептида, для которой нейросеть проекта Syntelly даёт корректное название по правилам ИЮПАК. Хотя авторы работы отмечают, что в названиях подобных больших молекул нейросеть пока часто делает ошибки
С номенклатурой ИЮПАК многие могли встретиться в курсе школьной химии, когда в задачке требовалось назвать «по ИЮПАК» изобутиловый спирт каким-нибудь 2-метилпропанолом-1. Собственно, эта номенклатура содержит свод правил, как следует назвать молекулу, чтобы потом по этому названию можно было однозначно восстановить его формулу. Эти правила дают конкретные указания, как нумеровать атомы, в какой последовательности записывать названия химических групп и т.д. Но если для простых молекул названия получаются однозначно определённые, то для сложных молекул возможны варианты, когда несколько названий будут правильными с точки зрения номенклатуры. Но обратная ситуация, когда одному названию соответствует несколько разных химических веществ, номенклатура исключает – в этом её несравненное достоинство.
По мере всё большей компьютеризации нашей жизни, и химической науки в том числе, идентификация вещества по его названию стала не такой важной, какой она была в прошлом веке. Компьютерам проще обрабатывать цифры и формулы, чем разбираться в семантике названий N-(4-гидроксифенил)ацетамида. Так появились более «цифровые» номенклатуры, например, SMILES (Simplified Molecular Input Line Entry System). Предыдущая молекула (а это обычный парацетамол) в номенклатуре SMILES будет выглядеть, как CC(=O)Nc1ccc(O)cc1. Тем не менее номенклатура ИЮПАК всё равно ещё в ходу: она используется в патентах, государственных и регуляторных документах, да и сами химики продолжают называть с помощью неё как новые, так и уже известные соединения.
Чтобы облегчить людям процесс присвоения правильных имён молекулам, существуют коммерческие программы. Несмотря на то, что сами правила алгоритмизированы, их всё равно настолько много и они весьма непростые, поэтому и компьютеризация номенклатуры – процесс трудозатратный. Так что не удивительно, что те, кто это уже сделали, хотят на этом заработать. Однако благодаря работе исследователей из Сколтеха, МГУ имени М. В. Ломоносова и компании Syntelly у всех ленивых и экономных химиков появился отличный инструмент, позволяющий быстро, правильно и, что немаловажно, бесплатно называть органические молекулы.
Чтобы решить эту задачу, исследователи использовали «Трансформер» – одну из самых мощных современных нейросетей, созданную компанией Google для машинного перевода с одного языка на другой. Но вместо перевода с русского на китайский команда обучила нейросеть «переводить» молекулу из структурного представления SMILES в наименование по ИЮПАК и наоборот. Для обучения и тестирования сети авторы исследования использовали самую большую в мире открытую базу химических веществ PubChem, содержащую около 100 миллионов соединений. Формулы молекул в формате SMILES, как и их названия в номенклатуре ИЮПАК, состоят из универсальных «кирпичиков» – букв, цифр, символов и их комбинаций.
Нейросеть, анализируя миллионы сочетаний формула-название может выработать свои внутренние «правила» перевода одного в другое. И оказалось, что делать это она может очень хорошо. На молекулах среднего размера её точность приближается к 100%, а в целом по тестовой выборке из базы данных PubChem точность перевода составила 98.9%. С чем модель справлялась плохо, так это названия очень больших молекул – в них были либо пропущены некоторые буквы, либо целые фрагменты молекулы. Нейросети подобного типа могут работать с длинными последовательностями, так что, возможно, что ошибки были связаны с небольшим количеством очень больших молекул, и нейросеть просто не успела обучиться на таких примерах.
Как отмечают авторы работы, они не просто сделали удобный инструмент для учёных, но, что более важно, им удалось показать, что нейронные сети способны достаточно точно решать алгоритмические задачи. «И человек, и нейронная сеть хорошо справятся, к примеру, с задачей различения фотографий кошек и собак, для которой невозможно эффективное алгоритмическое решение без машинного обучения. В то же время человек плохо перемножает многозначные числа, а простейший калькулятор делает это мгновенно и с абсолютной точностью – это пример чисто алгоритмической задачи, как и генерация названий по номенклатуре ИЮПАК», — поясняет Сергей Соснин, руководитель исследования.
Как-никак, химических элементов не только больше, чем букв в любом алфавите, но и соединяться они могут в «слова» длиной в несколько сотен букв и больше, что невозможно даже в немецком языке с его Donaudampfschiffahrtsgesellschaftskapitän. Да и самим химикам хотелось навести какой-то порядок в химической терминологии. Так появилась система наименований химических соединений – номенклатура ИЮПАК, которую разрабатывает Международный союз теоретической и прикладной химии.
Пример молекулы циклического пептида, для которой нейросеть проекта Syntelly даёт корректное название по правилам ИЮПАК. Хотя авторы работы отмечают, что в названиях подобных больших молекул нейросеть пока часто делает ошибки
С номенклатурой ИЮПАК многие могли встретиться в курсе школьной химии, когда в задачке требовалось назвать «по ИЮПАК» изобутиловый спирт каким-нибудь 2-метилпропанолом-1. Собственно, эта номенклатура содержит свод правил, как следует назвать молекулу, чтобы потом по этому названию можно было однозначно восстановить его формулу. Эти правила дают конкретные указания, как нумеровать атомы, в какой последовательности записывать названия химических групп и т.д. Но если для простых молекул названия получаются однозначно определённые, то для сложных молекул возможны варианты, когда несколько названий будут правильными с точки зрения номенклатуры. Но обратная ситуация, когда одному названию соответствует несколько разных химических веществ, номенклатура исключает – в этом её несравненное достоинство.
По мере всё большей компьютеризации нашей жизни, и химической науки в том числе, идентификация вещества по его названию стала не такой важной, какой она была в прошлом веке. Компьютерам проще обрабатывать цифры и формулы, чем разбираться в семантике названий N-(4-гидроксифенил)ацетамида. Так появились более «цифровые» номенклатуры, например, SMILES (Simplified Molecular Input Line Entry System). Предыдущая молекула (а это обычный парацетамол) в номенклатуре SMILES будет выглядеть, как CC(=O)Nc1ccc(O)cc1. Тем не менее номенклатура ИЮПАК всё равно ещё в ходу: она используется в патентах, государственных и регуляторных документах, да и сами химики продолжают называть с помощью неё как новые, так и уже известные соединения.
Чтобы облегчить людям процесс присвоения правильных имён молекулам, существуют коммерческие программы. Несмотря на то, что сами правила алгоритмизированы, их всё равно настолько много и они весьма непростые, поэтому и компьютеризация номенклатуры – процесс трудозатратный. Так что не удивительно, что те, кто это уже сделали, хотят на этом заработать. Однако благодаря работе исследователей из Сколтеха, МГУ имени М. В. Ломоносова и компании Syntelly у всех ленивых и экономных химиков появился отличный инструмент, позволяющий быстро, правильно и, что немаловажно, бесплатно называть органические молекулы.
Чтобы решить эту задачу, исследователи использовали «Трансформер» – одну из самых мощных современных нейросетей, созданную компанией Google для машинного перевода с одного языка на другой. Но вместо перевода с русского на китайский команда обучила нейросеть «переводить» молекулу из структурного представления SMILES в наименование по ИЮПАК и наоборот. Для обучения и тестирования сети авторы исследования использовали самую большую в мире открытую базу химических веществ PubChem, содержащую около 100 миллионов соединений. Формулы молекул в формате SMILES, как и их названия в номенклатуре ИЮПАК, состоят из универсальных «кирпичиков» – букв, цифр, символов и их комбинаций.
Нейросеть, анализируя миллионы сочетаний формула-название может выработать свои внутренние «правила» перевода одного в другое. И оказалось, что делать это она может очень хорошо. На молекулах среднего размера её точность приближается к 100%, а в целом по тестовой выборке из базы данных PubChem точность перевода составила 98.9%. С чем модель справлялась плохо, так это названия очень больших молекул – в них были либо пропущены некоторые буквы, либо целые фрагменты молекулы. Нейросети подобного типа могут работать с длинными последовательностями, так что, возможно, что ошибки были связаны с небольшим количеством очень больших молекул, и нейросеть просто не успела обучиться на таких примерах.
Как отмечают авторы работы, они не просто сделали удобный инструмент для учёных, но, что более важно, им удалось показать, что нейронные сети способны достаточно точно решать алгоритмические задачи. «И человек, и нейронная сеть хорошо справятся, к примеру, с задачей различения фотографий кошек и собак, для которой невозможно эффективное алгоритмическое решение без машинного обучения. В то же время человек плохо перемножает многозначные числа, а простейший калькулятор делает это мгновенно и с абсолютной точностью – это пример чисто алгоритмической задачи, как и генерация названий по номенклатуре ИЮПАК», — поясняет Сергей Соснин, руководитель исследования.
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.











