Что такое технология deepfake и как она работает
Когда deepfake-видео с Илоном Маском, исполняющим песню «Трава у дома», появилось в сети, оно моментально набрало миллионы просмотров на Youtube, а фейковый аккаунт Тома Круза не так давно взорвал TikTok. Так в чем же секрет технологии deepfake и как нейросеть стала самообучаемой?

Deepfake (дипфейк) — это синтезированный нейронными сетями реалистичный аудио-, видео- или фотоконтент. Термин включает и генерацию несуществующих фотографий (лиц, природы, картин — чего угодно), и face swap (перенос мимики одного человека на лицо другого), и озвучку предложений любым выбранным голосом, и оживление пейзажных фотографий (можно сделать подвижными изначально статичные снимки), а также всевозможные комбинации перечисленных пунктов. Современные технологии позволяют генерировать видео, которые достаточно трудно отличить от настоящего…
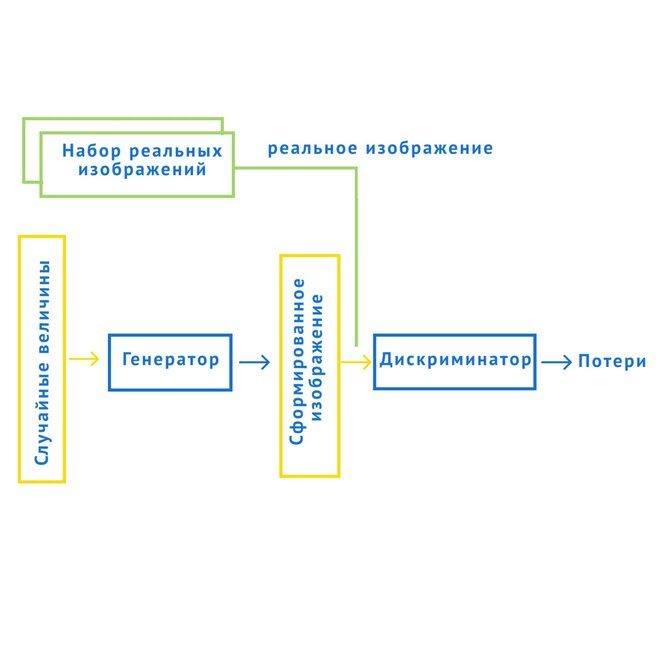
Схема работы генеративно-состязательных сетей (GANs)
«Чтобы обучить требовательную к вычислениям нейросеть, необходимы несколько суток расчетов, ну и конечно, мощный кластер видеокарт. Однако, этот подход даёт лучший результат!» — отмечает Лоран Акопян, генеральный директор iPavlov, исполнительный директор НИЦ АО «Швабе» в МФТИ, директор по разработке прикладного программного обеспечения Центра Компетенций НТИ по направлению «Искусственный интеллект».
Одно из решений, созданных на основе технологии GANs, — это FSGAN для faceswap, трансфер лиц на видео, когда ваша мимика полностью передается другому человеку. Здесь одна нейросеть учится подгонять лицо донора под параметры целевого видео (поворот головы, наклон в сторону или вперед), вторая переносит черты лица, а третья занимается image blending (слиянием изображений), чтобы картинка была более реалистичной, без разрывов или артефактов (частей изображения, которые снижают его реалистичность). Размытость части изображения, в частности, является примером артефакта.
Генерация лиц несуществующих людей на основе комбинации двух портретов с помощью StarGAN
Принципы архитектуры генеративно-состязательных сетей находят широкое применение в области Deepfake. Например, они позволяют решать такие задачи:
Генерация лиц несуществующих людей (StyleGAN2). Алгоритмы переноса стиля StyleGAN отделяют атрибуты высокого уровня (например, позы и лица) и низкого уровня (веснушки и волосы) и генерируют новое изображение без учителя. На основе этой архитектуры сайт под названием «This person does not exist» при каждом обновлении генерирует новый портрет несуществующего человека. Сеть обучили создавать не только новые лица, но и множество других объектов: например, автомобили, интерьеры.
Комбинирование нескольких лиц людей и их трансформация в одно новое лицо (StarGAN).
Ретушь фото. Например, нейросеть MichiGan может редактировать прическу на фотографиях.
Улучшение качества изображений (SRGAN — Super Resolution).
Трансформация изображений (Conditional GAN): для генерации вида здания по каркасу или одежды по скетчу, а также раскрашивания в определенные цвета.
Интерактивная генерация изображения по наброску (iGAN). GauGAN — программа от NVIDIA, которая превращает даже самые грубые наброски в фотореалистичные изображения.
Генерация новой картинки по описанию (StackGAN).
Генерация и стилизация видео по наброску (Vid2Vid).
Однако не все детали подвластны генеративно-состязательным сетям. Исследователи из MIT CSAIL изучили, какие объекты генеративным нейросетям сложнее всего синтезировать. На примере датасета LSUN churches они выяснили, что такие классы объектов, как люди, машины и ворота, игнорируются генератором нейросети.
В качестве модели для семантической сегментации (процесса разбиения изображения на родственные смысловые части) используется сеть семантического понимания Unified Perceptual Parsing. Нейросеть отмечает каждый пиксель (наименьший логический элемент/ячейку двумерного цифрового изображения), как принадлежащий объекту одного из 336 классов (количество классов, которые может распознавать конкретная сеть Unified Perceptual Parsing). Из оригинального изображения выделяются фрагменты, содержащие объекты. Данные фрагменты подаются на вход нейросети, решающей задачу создания картинки по наброску.
Аналогично с помощью Unified Perceptual Parsing распознаются объекты на созданной картинке. Далее интеллектуальной системой изучается распределение сегментаций объектов в обучающей выборке набора данных (от англ. Data set) LSUN churches и в сгенерированных изображениях, на основании чего делается вывод о том, объекты каких классов игнорируются, то есть не сегментируются сетью.

Original Image переводится в “скетч” (квадрат снизу под original image). Его пытается восстановить натренированная нейросеть: результат изображен на картинке reconstruction. Reconstruction также переводится в “скетч”, который мы сравниваем с первым
Второй недостаток заключается в том, что GANs нуждаются в предварительном обучении, так как мы сравниваемым вновь сгенерированное видео с оригиналом, и на основе этого обновляем параметры нейросети.

Пример работы FCGAN: после наложения лица на целевое видео результат сравнивается с этим же видео до манипуляций, нейросеть тренируется, пытаясь довести преобразование до идеального совпадения этих двух видео
По этой причине GANs требуют больших вычислительных мощностей и, несмотря на то что они дают самые качественные результаты, в популярных приложениях для обмена лиц (например, face swap) зачастую используются архитектура под названием «First order motion», разработанная выходцем из Беларуси Александром Сярохиным совместно с коллегами. Эта модель позволяет генерировать Deepfake без предобучения, на анимируемом объекте, накладывая на видео с нужными движениями фотографию любого человека. Для получения ожидаемого результата производится объединение человеческого лица, обнаруженного на фотографии, и видео, содержащего движущегося человека, лицо которого мы пытаемся заменить.
Таким образом, программа состоит из двух основных модулей: оценки движения и генерации изображения. Модуль оценки движения предназначен для анализа того, каким образом перемещается человек в целевом видео. А модуль генерации изображения предназначен для создания конечного видео с наложенными чертами лица другого человека.
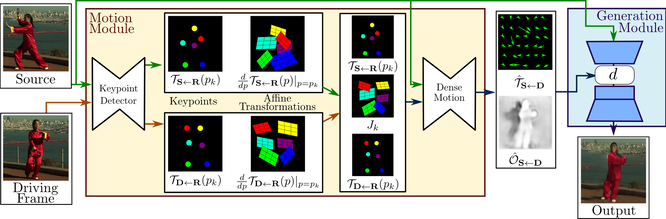
Архитектура “First order motion” для трансфера лиц
На вход системы обнаружения ключевых точек человеческого тела (под ключевыми точками подразумеваются точки, обозначающие положения частей тела, например: глаз, носа, локтей и т.д.) подаётся изображение и кадр из видео. Система извлекает ключевые точки и соответствующие им локальные преобразования относительно системы отсчета (исходного изображения), т.е. фактически задает «движение» кадра. Сеть переноса движения использует такое представление движения для создания оптического потока, который отображает видимое движение, основываясь на сдвиге каждой точки между соседними кадрами, и карты перекрытия объектов. Исходное изображение и выходные данные сети переноса движения используются модулем генерации изображения для визуализации целевого изображения.
Говоря простым языком, авторы модели научили сеть выделять движение по заданному видео и применять его к изображению, поэтому теперь пользователям доступна уже обученная на определенных категориях данных (датасеты лиц, человеческие тела) нейросеть. Ее можно легко и энергоэффективно использовать для замены лиц на видео.
Deepfake (дипфейк) — это синтезированный нейронными сетями реалистичный аудио-, видео- или фотоконтент. Термин включает и генерацию несуществующих фотографий (лиц, природы, картин — чего угодно), и face swap (перенос мимики одного человека на лицо другого), и озвучку предложений любым выбранным голосом, и оживление пейзажных фотографий (можно сделать подвижными изначально статичные снимки), а также всевозможные комбинации перечисленных пунктов. Современные технологии позволяют генерировать видео, которые достаточно трудно отличить от настоящего…
Что стоит за Deepfake?
Наиболее впечатляющие результаты дает использование генеративно-состязательных сетей (GANs — Generative Adversarial Networks), представляющих собой 2 нейронные сети, тренирующиеся одновременно: одна из них (генератор) учится генерировать новые экземпляры данных, а вторая (дискриминатор) «штрафует» первую за некачественный фейк, если видит, что характерные признаки созданной картинки сильно отличаются от настоящей. Эту концепцию, напоминающую игру в полицейского и фальшивомонетчика, предложил в 2014-м году Ян Гудфеллоу (Ian Goodfellow).Схема работы генеративно-состязательных сетей (GANs)
«Чтобы обучить требовательную к вычислениям нейросеть, необходимы несколько суток расчетов, ну и конечно, мощный кластер видеокарт. Однако, этот подход даёт лучший результат!» — отмечает Лоран Акопян, генеральный директор iPavlov, исполнительный директор НИЦ АО «Швабе» в МФТИ, директор по разработке прикладного программного обеспечения Центра Компетенций НТИ по направлению «Искусственный интеллект».
Одно из решений, созданных на основе технологии GANs, — это FSGAN для faceswap, трансфер лиц на видео, когда ваша мимика полностью передается другому человеку. Здесь одна нейросеть учится подгонять лицо донора под параметры целевого видео (поворот головы, наклон в сторону или вперед), вторая переносит черты лица, а третья занимается image blending (слиянием изображений), чтобы картинка была более реалистичной, без разрывов или артефактов (частей изображения, которые снижают его реалистичность). Размытость части изображения, в частности, является примером артефакта.
Генерация лиц несуществующих людей на основе комбинации двух портретов с помощью StarGAN
Принципы архитектуры генеративно-состязательных сетей находят широкое применение в области Deepfake. Например, они позволяют решать такие задачи:
Генерация лиц несуществующих людей (StyleGAN2). Алгоритмы переноса стиля StyleGAN отделяют атрибуты высокого уровня (например, позы и лица) и низкого уровня (веснушки и волосы) и генерируют новое изображение без учителя. На основе этой архитектуры сайт под названием «This person does not exist» при каждом обновлении генерирует новый портрет несуществующего человека. Сеть обучили создавать не только новые лица, но и множество других объектов: например, автомобили, интерьеры.
Комбинирование нескольких лиц людей и их трансформация в одно новое лицо (StarGAN).
Ретушь фото. Например, нейросеть MichiGan может редактировать прическу на фотографиях.
Улучшение качества изображений (SRGAN — Super Resolution).
Трансформация изображений (Conditional GAN): для генерации вида здания по каркасу или одежды по скетчу, а также раскрашивания в определенные цвета.
Интерактивная генерация изображения по наброску (iGAN). GauGAN — программа от NVIDIA, которая превращает даже самые грубые наброски в фотореалистичные изображения.
Генерация новой картинки по описанию (StackGAN).
Генерация и стилизация видео по наброску (Vid2Vid).
Однако не все детали подвластны генеративно-состязательным сетям. Исследователи из MIT CSAIL изучили, какие объекты генеративным нейросетям сложнее всего синтезировать. На примере датасета LSUN churches они выяснили, что такие классы объектов, как люди, машины и ворота, игнорируются генератором нейросети.
В качестве модели для семантической сегментации (процесса разбиения изображения на родственные смысловые части) используется сеть семантического понимания Unified Perceptual Parsing. Нейросеть отмечает каждый пиксель (наименьший логический элемент/ячейку двумерного цифрового изображения), как принадлежащий объекту одного из 336 классов (количество классов, которые может распознавать конкретная сеть Unified Perceptual Parsing). Из оригинального изображения выделяются фрагменты, содержащие объекты. Данные фрагменты подаются на вход нейросети, решающей задачу создания картинки по наброску.
Аналогично с помощью Unified Perceptual Parsing распознаются объекты на созданной картинке. Далее интеллектуальной системой изучается распределение сегментаций объектов в обучающей выборке набора данных (от англ. Data set) LSUN churches и в сгенерированных изображениях, на основании чего делается вывод о том, объекты каких классов игнорируются, то есть не сегментируются сетью.
Original Image переводится в “скетч” (квадрат снизу под original image). Его пытается восстановить натренированная нейросеть: результат изображен на картинке reconstruction. Reconstruction также переводится в “скетч”, который мы сравниваем с первым
Второй недостаток заключается в том, что GANs нуждаются в предварительном обучении, так как мы сравниваемым вновь сгенерированное видео с оригиналом, и на основе этого обновляем параметры нейросети.
Пример работы FCGAN: после наложения лица на целевое видео результат сравнивается с этим же видео до манипуляций, нейросеть тренируется, пытаясь довести преобразование до идеального совпадения этих двух видео
По этой причине GANs требуют больших вычислительных мощностей и, несмотря на то что они дают самые качественные результаты, в популярных приложениях для обмена лиц (например, face swap) зачастую используются архитектура под названием «First order motion», разработанная выходцем из Беларуси Александром Сярохиным совместно с коллегами. Эта модель позволяет генерировать Deepfake без предобучения, на анимируемом объекте, накладывая на видео с нужными движениями фотографию любого человека. Для получения ожидаемого результата производится объединение человеческого лица, обнаруженного на фотографии, и видео, содержащего движущегося человека, лицо которого мы пытаемся заменить.
Таким образом, программа состоит из двух основных модулей: оценки движения и генерации изображения. Модуль оценки движения предназначен для анализа того, каким образом перемещается человек в целевом видео. А модуль генерации изображения предназначен для создания конечного видео с наложенными чертами лица другого человека.
Архитектура “First order motion” для трансфера лиц
На вход системы обнаружения ключевых точек человеческого тела (под ключевыми точками подразумеваются точки, обозначающие положения частей тела, например: глаз, носа, локтей и т.д.) подаётся изображение и кадр из видео. Система извлекает ключевые точки и соответствующие им локальные преобразования относительно системы отсчета (исходного изображения), т.е. фактически задает «движение» кадра. Сеть переноса движения использует такое представление движения для создания оптического потока, который отображает видимое движение, основываясь на сдвиге каждой точки между соседними кадрами, и карты перекрытия объектов. Исходное изображение и выходные данные сети переноса движения используются модулем генерации изображения для визуализации целевого изображения.
Говоря простым языком, авторы модели научили сеть выделять движение по заданному видео и применять его к изображению, поэтому теперь пользователям доступна уже обученная на определенных категориях данных (датасеты лиц, человеческие тела) нейросеть. Ее можно легко и энергоэффективно использовать для замены лиц на видео.
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.
+1
Понял только, что тик-ток наконец-то взорвали.
Надеюсь, что восстанавливать/чинить его никто не будет…
- ↓
-1
Никакое это не deepfake-видео. Илон Маск давно эту песню поет, я на его концерте был.
- ↓
+1
«Наиболее впечатляющие результаты дает использование генеративно-состязательных сетей»-на фоне дегенерации разума населения. Образование в СССР было эталонным. Получение знаний за деньги-не является образованием.
- ↓
+3
Хороший анекдот про платное образование:
Встречаются два однокурсника. Один говорит другому: — Как подумаю какой из меня инженер — то боюсь к доктору идти.
- ↑
- ↓
0
Да так и есть!
- ↑
- ↓











